written on 11/19/2018
Learn to visualize React components by parsing JSX with Babel
It is natural that big data structures or components exist in large JavaScript applications. Sometimes these data structures or components are the heart of your application but are really difficult to understand for new developers or non-technical people which work on the project. In these cases, there is the possibility to visualize the data structure or component itself to make the data structures and components more accessible. In most cases doing this manually once is enough but if you have changing components or data structures, then automation would be a great thing to have. This automation step will be explained in this blog article. What we will do here is the following:
- Learn to parse programming languages
- Get the hang of JavaScript parsing with Babel
- Create an abstract syntax tree (AST) of a React component
- Reduce this abstract syntax tree (AST) to a better format
- Visualize the improved format of the abstract syntax tree
The structure of programming languages
Every programming language is a construct of logical operations. In the end, every language is somehow compiled to some sort of code the computer or the running system can understand. Enabling the language to be transformed requires a specific format. This is where abstract syntax trees come into play. A tree in this sense here is just a root node with multiple children nodes which can also have children nodes. The important part is that there is just one root node. Each node in the abstract syntax tree defines some structure of the source code. For example, in HTML the a-tag with a text inside <a>Hello World</a> would be two nodes. The first node is the HTML tag with the type a and it would have a children node which might be a Text node with the value Hello World inside. The root node is the HTML node in this case. I need to mention here that HTML is per se no programming language but is parsable like other languages.

To understand a little bit more complicated example, let us look at the following structure HTML structure:
1<div>2<h1>Hello World</h1>3<span>Description</span>4</div>
It is a simple div element with a heading and an inline text element. The structure of the tree would look like the following image.
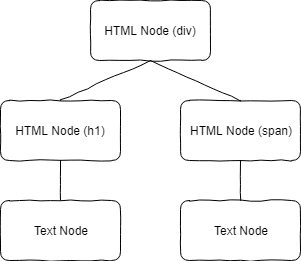
As you can see we have the one root node which is basically the div element and contains children nodes which are also HTML nodes but then also just include one child which is the text. These visualizations are what I wanted to achieve to display React components because they got a similar structure. To do so we need to be able to parse the JavaScript responsible for it.
Get the hang of JavaScript parsing with Babel

Babel is a JavaScript compiler and provides a lot of functionality. Normally it used to compile ES6 and newer syntax to an old version so JavaScript can be run in every browser but developers are able to write modern syntax. This is extremely useful for developers because they do not need to write code which is compatible with Internet Explorer.
1const a = "Hello";2const b = "World";3const c = `${a} ${b}`;
In the image above you can see some ES6-compliant code which will run on most modern browsers but trying to run this code in Internet Explorer will just fail because it does not support this modern syntax like const [MDN] or Template Literals [MDN]. But because those new features could be in a way rewritten, Babel is able to compile this source code to a version of source code that is runnable even in old browsers like Internet Explorer. You can see the compiled code below but also try it out on the Babel website. They provide a REPL where you can play around: https://babeljs.io/en/repl
1const a = "Hello";2const b = "World";3const c = a + "" + b;
Babel seems awesome already but how is it doing stuff like this?
Babel has a lot of utilities but the first utility which is used is the Babel parser. It can be downloaded separately from npm and you can find the documentation about the package here: https://babeljs.io/docs/en/babel-parser. Basically, the functionality can be described as quoted from the documentation:
The Babel parser generates AST according to Babel AST format. It is based on ESTree spec […]
The package provides two functionalities but we will focus just focus on the parse functionality. It is a single function with two parameters. The first parameter is the code to be parsed and the second optional parameter are options given to the function. The output of this function will be an abstract syntax tree. To get an idea of how this abstract syntax tree could look like we are going to use the tool AST explorer. It is a web application where you can paste some code and it will give you an abstract syntax tree to visualize how this code is getting parsed. You can find the application here: https://astexplorer.net/
1const a = 5;
This is the source code which we will paste into the AST explorer. Be sure to set the parser from acord to babylon . Babylon is the parser previously used in Babel but gives you more or less the same output as @babel/parser . Pasting the source code inside gives you a similar output like the following JSON:
1{2// ...3"program": {4"body": [5{6"type": "VariableDeclarator",7// ...8"id": {9"type": "Identifier",10// ...11"name": "a"12},13"init": {14"type": "Literal",15// ...16"value": 5,17"rawValue": 5,18"raw": 519}20}21],22"kind": "const"23}24}
You can see that this represents a tree somehow because there is just one root node which is program . Then you get more and more into nested into declarations and other elements. With larger programs and source code, this tree will grow dramatically in size. So what Babel does now, is to check for these type of declarations and so on and analyzing the tree structure to see if it can transform some nodes. In this example to transform const to var it would be easy to just check the whole tree for nodes with the type VariableDeclaration and to check if the kind property is const . If this is the case the tree could be rewritten to be of thekind var . With this structure, we can then create JavaScript out of the tree again. This is also given in a Babel package but I will not demonstrate this in this blog article. It is enough to understand that this is possible since it is of no importance for us.
This is the basic structure of how every compiler works. A language is parsable into an abstract syntax tree and can be transformed then. It is a deep computer science topic, handled mostly in university courses but it is really good to understand because it could be used in various work scenarios too.
Create an abstract syntax tree (AST) of a React component
1export const Welcome = (props) => {2return (3<div>4<div>5<p>dawwadwad</p>6<div>7<span>awdwad</span>8</div>9</div>10<h1>Hello, {props.name}</h1>11</div>12);13};1415export default Welcome;
With the knowledge we have gathered we can start parsing React components. On the left, you can see a simple functional React component. Since JSX is “JavaScript-conform” syntax we can straight up start trying to parse it. For this let us create a new Node.js project and add the dependency @babel/parser to the project.
After we have done this we can start with writing the code to parse the React component. It should be relatively easy. We need to import the parser and the file read utility from Node.js. After this, we read the content of the React component into a variable and then put this variable as a parameter to the parsing functionality. The result we get back from the function should be the abstract syntax tree of the component. The source code should look similar to this:
1const babelParser = require("@babel/parser");2const fs = require("fs");3const content = fs.readFileSync(__dirname + "/Welcome/index.js", "utf8");4const ast = babelParser.parse(content);5console.log(JSON.stringify(ast));
Executing this code resolves in an error though 🤷 SyntaxError: Unexpected token (3:4) . This is because Babel cannot parse JSX and also does not support modules by default. For this, we need to pass a configuration object to the parse function of the babelParser . The source code after this should look like the following image:
1const babelParser = require("@babel/parser");2const fs = require("fs");3const content = fs.readFileSync(__dirname + "/Welcome/index.js", "utf8");4const ast = babelParser.parse(content, {5sourceType: "module",6plugins: ["jsx"],7});8console.log(JSON.stringify(ast));
After this, our console will put out a really long JSON. This JSON represents the abstract syntax tree of the React component. It is super long but includes all details to do heavy operations on the abstract syntax tree. You can find the full JSON in this gist.
This was quite easy and really shows how great the architecture of Babel is. The tool itself is doing so much stuff and also deals with one of the most complicated things in the programming world in my opinion but it splits down the functionality into small reusable modules so you can actually understand one simple module to work with it. Huge thanks to the great Babel team :)
Reduce this abstract syntax tree (AST) to a better format
The current abstract syntax tree shown in this gist contains 600 lines of JSON is quite hard to work on. Our task is to visualize the HTML structure of the JSX component in this case. So to get an idea of where this information is, we need to observe the abstract syntax tree somehow. I reduced an element of the tree somehow with the important information for us which is shown in the following image.
1{2"type": "JSXElement",3// ...4"openingElement": {5"type": "JSXOpeningElement",6// ...7"name": {8"name": "p",9"type": "JSXIdentifier"10// ...11}12},13"closingElement": {14"type": "JSXClosingElement",15// ...16"name": {17"name": "p",18"type": "JSXIdentifier"19// ...20}21},22"children": [23{24"type": "JSXText",25"value": "dawwadwad"26// ...27}28]29}
You can see that we have a top-level node which is of the type JSXElement . Inside we have properties like openingElement and closingElement but also children . In this case we should focus on JSXElement nodes and look for their properties openingElement.name.name because this is the information we are looking for. If we scan the whole JSON for nodes of the type JSXElement , we will find six nodes of this type, where openingElement.name.name are the following:
- div
- div
- p
- div
- span
- h1
This structure can be explained because Babel is traversing the tree recursively. It will go from node to the next possible children node and then tries to go to the next node until it is not possible anymore. Every node visited will be marked with a marker and if the current pointer is at a point where it cannot find a not-visited node it will go back to its parent node. Then the algorithm will try to go to more unmarked children nodes. This will be done as long as there are unvisited nodes. In our case, it will go deeply into the JSX component first to see the inner span and p tag and going back to the root div and then visiting the other h1 tag.
What we want to have in the end, would be a representation like this:
1{2"name": "div",3"children": [4{5"name": "div",6"children": [7{ "name": "p", "children": [] },8{ "name": "div", "childre": [{ "name": "span", "children": [] }] }9]10},11{ "name": "h1", "childre": [] }12]13}
This is a completely reduced version of the abstract syntax tree with just the structure of the HTML elements in the JSX component. To get there we need to reduce the original abstract syntax tree given by the Babel parser. You can find the full code inside this file of the repository I created: https://github.com/igeligel/jsx-to-simple-ast/blob/master/src/parser.js
1const rawAst = babelParser.parse(content, {2sourceType: "module",3plugins: ["jsx"],4});56const initialAst = rawAst.program.body.find(7(astNode) => astNode.type === "ExportNamedDeclaration",8).declaration.declarations[0].init.body.body[0].argument;
The first part for us is to find the body of the file. I called this initialAst because this is the first reduced version of the abstract syntax tree. We scan first for a named export declaration and then go through the right declarations to find the body of the declaration. It is called with an argument which is actually the value of the export statement. This is the “most raw” tree node we can get here. From now on we have one root node with several children and repeated in a way so we can easily traverse the tree.
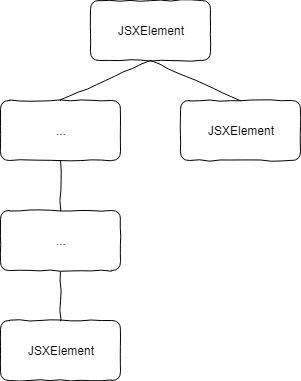
Traversing the tree is normally a recursive function. This is because we work here node for node and just scan if a node is of some type and then check if it has children. So the first step would be to go through every node and check if the type is JSXElement. If not, we just skip the node more or less and do not do anything with it. This is because we cannot delete the node directly because then we will not have a structure anymore because the parent-child relation will get lost. Imagine a ... node in the image next to the text will just get deleted. The reference to the children nodes would also be lost and we would not know anymore that the JSXElement node on bottom is actually referenced to the root node. What we do instead is to give a reference of the parent's children properties to the current node so we can assign the proper children there. If we discover a new node of the type JSXElement we assign a new array of children to this node and pass the children again to the real AST children nodes. So basically we do this for every node and this is why a recursive function is the best we can do here now. You can see this functionality in the following code snippet:
1const reduceAstNode = (oldNode, currentNode) => {2let element = {};3if (currentNode.type === "JSXElement") {4element = {5name: currentNode.openingElement.name.name,6children: [],7};8oldNode.push(element);9}10if ("children" in currentNode) {11currentNode.children.forEach((node) =>12oldNode.length > 013? reduceAstNode(element.children, node)14: reduceAstNode(oldNode, node),15);16}17return oldNode;18};
oldNode in this example is just a new array being passed to the function. So we actually create a completely new tree here and just passing the nodes of the new tree around to not destroy the order of the old tree which is the current node.
Combining the initial abstract syntax tree now with this functionality will give us the following reduced abstract syntax tree:
1[2{3"name": "div",4"children": [5{6"name": "div",7"children": [8{ "name": "p", "children": [] },9{ "name": "div", "children": [{ "name": "span", "children": [] }] }10]11},12{ "name": "h1", "children": [] }13]14}15]
That is exactly what we wanted to achieve. Now we have a reduced practical form of the HTML structure represented as a simple abstract syntax tree. Now we can work with this tree structure. Possibilities are:
- Generating HTML code
- Generating diagrams
- Analyzing nesting and other complexity trends
The possibilities are endless here. It is up to your task on what to do with it.
Visualize the improved format of the abstract syntax tree
Visualizing is the last step what I wanted to achieve with this project. After some research, I have not found a plug-and-play solution for this problem but I have found a great example on codepen of a D3.js tree layout solution zhulinpinyu and ported it into a codesandbox.
To change the structure of the tree we need to go to the index.js file of the src folder. In there we can find the exact configuration of the tree generated by our Node.js program. If you changed the React component structure inside this Node.js project and let the project run again you will see the changed output. Just paste it into the codesandbox and let your tree get rendered.
There are many more possibilites to visualize things with JavaScript. If you are interested in those diagrams I can definitely recommend the following tools and libraries:
- codesandbox.io — an awesome online editor for JavaScript applications
- d3.js — A library for creating diagrams
- jsx-to-simple-ast — The repository of the tree generator
Thanks for reading this. You rock 🤘 Also check my other blog articles like Function parameters in JavaScript, Learn how to refactor Vue.js Single File Components with a real-world example or Auto formatters for Python. If you have any feedback or want to add something to this article just comment here. You can also follow me on twitter or visit my personal site to stay up-to-date with my blog articles and many more things.
You might also like
Auto formatters for Python
🔥Save time by using the best auto formatters for python - a comparison to find the best for Python 2 and Python 3
Vue.js review of 2017
Vue.js had amazing growth throughout 2017, after the release of version 2 of the framework in 2016 the ecosystem grew drastically. This and more in Vue.js in 2017 is covered here.